Pointers to Function
A pointer to a function is the simplest type of abstraction you can have in programming. A function is a subprogram that may receive a piece of data from the superprogram (called its arguments or parameters) and may return a piece of data to the superprogram (called its return value).
For example, let's say we have two functions, SortAlphabetically(a: file, b: file) -> isAFirst? and SortByFileSize(a: file, b: file) -> isAFirst?. Both functions take two arguments of type file, a and b, and return whether a comes before b or not. In other words, they have the same function signature. This is a common property that we can abstract.
If we had a function pointer such as currentSortingMethod: *(a: file, b: file) -> isAFirst?, a superprogram could have the following line of code:
currentSortingMethod(a, b);And then some sorting method would be executed. Which sorting method specifically will be executed isn't important, because we're referring to an abstraction of sorting functions, not to any concrete sorting function in particular.
Depending on the current value of the currentSortingMethod pointer variable, the SortAlphabetically subprogram could be executed, or the SortByFileSize subprogram could be executed, or any other function that matches the abstracted function signature.
Imagine a program as being a train on a rail track. A train isn't a car. It can't freely move around. It must follow the rail track. Now imagine there was a point where the track split in two, and you had a lever that let you control which of the two tracks the train would follow. This is more or less how function pointers work. Depending on the state of the lever, the train will go to one track or the other.
Note: the syntax used above is pseudo code and and not from an existing programming language.

In languages that don't have the concept of pointers, such as Javascript and Python, the same concept may exist as "references" to functions instead.
Union Structure Types
An union structure type is an abstraction of multiple data structures that assign the same meaning to bytes in certain positions of the data structure.
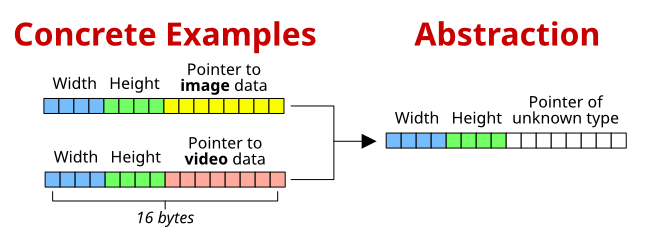
For example, let's say we have two data structures, Circle and Square. The Circle structure has a field called radius. The Square structure has a field called sideLength. In practice, it's likely these fields would have the same type (e.g. 4 byte floating point number), but let's theorize that these two types are incompatible with each other, so we can't abstract them.
Due to how CPU's work, it's often beneficial for performance to have all data of an application stored closely in RAM, as the CPU cache will fetch data from the RAM in memory addresses nearby the data that is being used at the moment.
This becomes a problem when creating lists of items in a contiguous array structure. To create an array of N items, we need to reserve enough contiguous space in memory for N items, and in order to do this, we need to know how many bytes each item requires. If, for example, we wanted to create an array of Circle that contains 3 items, we would need enough bytes to store 3 radius fields, and that depends on how many bytes a single radius field requires to store its value.
If radius and sideLength have different sizes, then we can't fit a Circle in the memory reserved for a Square, or vice-versa. This is generally not a problem for most programs, but it can become a problem in programs that need to process a lot of data very quickly, such as games, image editors, and video players (more specifically, video decoders).
In this case it's possible to abstract these two incompatible data structures into an unified data structure that encompasses all of them by adding a field to distinguish the type of data structure contained in a span of memory. This is a rather artificial abstraction, as we need to introduce a new property to the objects we want to abstract just so they all have a common property that we can abstract. For example:
union Shape {
structure Square {
isSquare? = true,
sideLength: SquareLength,
},
structure Circle {
isSquare? = false,
radius: CircleRadius,
}
}Above, the union Shape can abstract the field isSquare? that we have added to our structures. By using this new field, we can tell whether a given Shape has a sideLength field or a radius field.
The total size of a Shape structure is at least* the size of the largest structure it can contain.
For example, let's say that the size of isSquare? is 1 byte, sideLength is 8 bytes, and radius is 4 bytes.
On any Shape, the first byte (at offset zero) will always store the value of isSquare? regardless of what concretization is stored. If the Shape is a Square, then the bytes at offsets 1 to 8 will store the value of sideLength. However, if the Shape is a Circle, then bytes 1 to 4 will store the value of radius instead, and bytes 5 to 8 will be unused. The unused bytes for alignment purposes are also called padding.
To help visualize this, let's say we set the variable fields to their maximum value by setting all bytes to 0xFF, but we leave the padded bytes as 0x00. This is what each byte in each byte offset would look like in comparison:
Offset: 00 01 02 03 04 05 06 07 08
Circle: 00 FF FF FF FF FF FF FF FF
Square: 01 FF FF FF FF 00 00 00 00Through our Shape abstraction we always know what the byte at offset 00 means, i.e. which field it refers to. It's always going to be isSquare?. And its value could be 0x00 when isSquare? is false, and 0x01 when it's true.
Thanks to this padding the size of a Shape is constant. It's always going to be 9 bytes. This means if we want to store 100 Shape's in a contiguous array, we can simply reserve 900 bytes and it's going to work regardless of whether our shapes are all circles, all squares, or a mix of circles and squares.
*: it's worth noting that in practice it's a bit more complicated than that. In low-level programming structures are often aligned to the CPU architecture the program is being compiled for, which means means that a 9 byte structure in a 64 bit architecture may be padded to occupy 16 bytes (128 bits).
As you may imagine, this technique is used in contexts far more complex than this. An example are events processed by graphical user interfaces. In this case, the distinguishing field tends to be a special type called an enumeration (enum). An enumeration gives names to many possible values of a specific type. We could have an union called Event whose distinguishing field is called kind, of type EventKind. EventKind could be MouseMoveEvent, MouseButtonPressEvent, MouseButtonReleaseEvent, KeyPressEvent, KeyReleaseEvent, etc. The enumeration could assign a different number to each of these names, e.g. 0x01 is MouseMoveEvent, 0x02 is MouseButtonPressEvent, and so on.
Through this, you can have a single data structure that can hold any type of event and can tell you what type of event it's holding.
In some cases, it's not a good idea to put the data structure inside the union due to how memory ownership is designed in the program, or because some structures are just extremely large in comparison to others so the padding becomes problematic. Unions can still be used then by having pointer to the data instead of embedding the data, e.g.:
union Event {
structure MouseButtonPressEvent {
kind = EventKind.MouseButtonPressEvent,
pointer: *MouseButtonPressEventData
},
structure KeyboardKeyReleaseEvent {
kind = EventKind.KeyboardKeyReleaseEvent,
pointer: *KeyboardKeyReleaseEventData
}
}Above, we can use the common kind field to tell what is the type of the pointer field in an Event structure.
This is necessary because in low-level programming languages there is no way to tell the type of the data pointed by a pointer of unknown type (e.g. a void* pointer in C and C++). A pointer is simply a memory address. In our Event above, we will have a kind field that is of EventKind type, and a pointer that points either to a MouseButtonPressEventData or to a KeyboardKeyReleaseEventData. These could be completely different types of event data with nothing in common, so there is no way to abstract them. In other words, there is no common way to use pointers of different types. The only thing we can do with a random memory address (also called an opaque pointer), is store it and pass it around the program. Only a subprogram that knows the type of the pointer can use its data for anything.
In high level programming languages there is a concept called reflection that lets you tell the type of a pointer or reference at runtime.
Superclasses and Virtual Methods in Object Oriented Programming
In object oriented programming (OOP), abstraction typically refers to using a superclass from which subclasses are derived. The way the C++ programming language does it in practice is just combining the two concepts we've already learned in the two sections above, but let's start from the beginning first.
In OOP, data structures are paired with methods that operate on their data. This coupling is done for various reasons: organizing code, namespacing, because nobody came up with a better way to program yet, and, finally, because it allows you to abstract the behavior of a set of objects into a type called their superclass or base class.
Let's say that we have two objects: a coal power plant and a nuclear power plant. What we can abstract from these two objects is that they are both capable of generating power. Thus we have the superclass:
class PowerPlant {
getEmployeeCount() -> number;
[virtual] demolish() -> void;
[undefined] generatePower() -> Power;
}In general, we have 3 types of methods in a superclass.
First we have non-virtual methods, like getEmployeeCount(). This is a subprogram implemented by PowerPlant. It's always the same subprogram that will be run no matter the subclass. In other words, a non-virtual method is a subprogram that subclasses can't alter.
Then we have virtual methods like demolish(). In this case, PowerPlant provides a default implementation for the method—e.g. just use TNT to explode everything—but it's possible for subclasses to modify this behavior if they need it. In this case, we probably don't want to use TNT with our nuclear power plant. I'm not a nuclear engineer, though, so who knows!
Finally, we have undefined methods like generatePower(). These are also called "abstract" methods in some programming languages. An undefined method is simply a method that a superclass doesn't define the behavior of. This is different from a method that does nothing. For example, in this case generatePower() must return some Power, which means it has to generate it somehow. Our abstract superclass has no idea how to generate power in concrete terms, so it can't implement this behavior. On the other hand, anyone who wants a power plant wants a power plant that can generate power. This means that PowerPlant itself isn't a valid PowerPlant type since it doesn't implement all the methods it abstracts. In some programming languages this is called an "abstract class," which is a class that can't be instantiated into an object because it doesn't have a complete implementation of the interface it exposes to rest of the program.
Subclasses inhering from PowerPlant would have to implement generatePower or they would be abstract classes themselves as well. On the other hand, they don't need to implement demolish as the existing implementation can be inherited from the superclass, and they can't modify getEmployeeCount as it's not a virtual method. If a subclass does try to implement getEmployeeMethod, we say that it "hides" the superclass method because subprograms that make use of the superclass won't be able to access it as it's not virtual. Let's see an example to understand this better:
class PowerPlantBattery inheriting from Battery {
charge(energySource: *PowerPlant) -> void {
while(not this.isCharged?) {
this.energy.add(energySource.generatePower());
}
}
}Above, we have a PowerPlantBattery that is charged directly from a PowerPlant somehow. Observe that it uses the generatePower method that PowerPlant exposes. PowerPlantBattery doesn't know how its power is being generated, nor should it care. This is an implementation detail. When we deal with abstractions, we shouldn't concern ourselves with how the concrete subprograms those abstractions represent were implemented. In particular, the great thing about these abstractions is that we could get a FissionPowerPlant in the future and the code for this battery would still work even though it was created before this new power plant existed.
If the program doesn't know the specific type of the pointer *PowerPlant, how can we use it?
Low-level programming language that implement object oriented programming make use of unions to implement the class inheritance system. In the case of C++, an abstracted field that is added by the language to instances of subclasses to make OOP work is the vptr, which points to a vtable, short for "virtual table."
How VTables Work
A vtable holds pointers to the implementations of virtual methods. Methods aren't really different from functions in the way they work, so a pointer to a function and a pointer to a method are essentially the same thing.
When an executable file or library is loaded in memory, the machine code of every subprogram in the executable is also loaded in memory somewhere. A pointer to a function simply points to the memory address of the first byte of that function's algorithm in memory.
When we create a class that has virtual methods, a vtable will be created for the class that contains the memory address of the implementation of each virtual method. In the case of abstract virtual methods like generatePower, which have no default implementation, the pointer points to the null pointer address, which is a special value used when a pointer doesn't point to a real memory address. In fact, in the C++ programming language you declare an abstract virtual method by setting it to 0, which is typically (but not always) the value of the null pointer address.
When we create a subclass, a vtable will also be created for the subclass. This subclass's vtable will have the same memory addresses as the superclass vtable by default. When we override a virtual method in a subclass, what is really happening is that a pointer in the subclass vtable will be changed to point to its implementation of the virtual method. For example, if we override generatePower in a CoalPowerPlant, its value will stop being null and will instead point to the memory address of CoalPowerPlant.generatePower in memory.
Each subclass has its own vtable, so the vtable for NuclearPowerPlant will have the address of NuclearPowerPlant.generatePower for its generatePower pointer.
When an object instantiated from a non-abstract superclass or subclass, there will be a hidden vptr field in the object that tells C++ the memory address of the vtable that contains the pointers to the subprograms. Since every superclass and subclass has its own vtable, this could be used in reflection to tell the type of a random pointer, although it wouldn't work for classes don't have a vtable. For example, given the following C++ code:
PowerPlant* p = new NuclearPowerPlant();
p->generatePower();What is really happening is something like this:
PowerPlant* p = new NuclearPowerPlant();
VTableForPowerPlant* t = p->vptr;
Power (PowerPlant::*generate)() = t->generatePower;
Power x = p->*generate();This looks a bit complicated due to C++'s pointer syntax. Normally, a method can be called like this: plant.generatePower(). But if plant is a pointer, it must be called like this: plant->generatePower(). On any method, the instance of the object (in this case, plant), must be passed to the subprogram so the algorithm can have access to the object's data.
C++ does this automatically in these cases, and the instance's fields can be accessed by the special variable this inside a method's scope. Python, on the other hand, requires you to explicitly write self in a method's arguments.
In either case, it's a fact that a method needs to know where the data of its object is on memory in order to access it, whether it appears in the list of arguments of the function or not doesn't really matter. This means that when we have a pointer to a method like generatePower, it needs to be called in a way that passes an instance of an object that will become the this in the subprogram. This is done in C++ with p->*generate, where p in this case is a pointer to an instance. Due to C++'s static type safety checks, this also requires us to say what is the type of this for the function pointer, and this is done with PowerPlant::*. It's a rather weird syntax, to be honest.

vptr of instances and the vtable of classes on some Object Oriented Programming implementations, such as C++.Abstractions in Interface Oriented Programming
In high-level programming languages, abstractions tend to be more powerful as we're not restricted to low-level concepts like bytes and memory addresses. One example is the notion of interface oriented programming popular in Java and C#.
In interface oriented programming, we can abstract any property of any object, and multiple abstractions can easily overlap on the same object. This is different from how OOP works because in OOP it's very easy to inherit from a single abstract class but things become far more complex if we tried to inherit from two or more base classes (a concept called multiple inheritance).
The idea behind "interfaces" in this sense is that we declare an "interface" that tells us what methods an object must implement to implement an interface. For example:
interface IPowerGenerator {
generatePower() -> Power;
}Ideally, ANYTHING that has a method called generatePower with the signature above would be a valid implementation of the interface. That's how it works in Typescript: anything that implement the methods of an interface implicitly implemented the interface. Unfortunately, it's not how it works in C# and Java. In these languages, we must explicit declare that we are implementing a given interface in order for it to count. After we do that, we can use anything that implements IPowerGenerator with any subprogram that requires an IPowerGenerator.
The ability to abstract only a single method from an object sometimes leads to the creation of countless interfaces for every possible thing you can imagine. For example, an INameHaver or INameGetter being an interface for objects that implement a getName method which returns the name of the object. The I prefix in interface names is by convention.
Duck-Level Abstraction
The final stage of abstraction in programming is duck typing. In duck typed languages like Python, if it quacks like a duck, it's a duck. In other words, you can pass any object to any function and you find out if it works or not if the program crashes when you run it. If it works, then it's because you passed an object thar properly implements the properties that the subprogram expects, e.g. the subprogram expected a duck for quacking, you gave it something that quacks, that sounds good enough for it so it works.
Under the hood, this is possible because duck-typed keep track of the names of the fields at runtime.
In low-level compiled languages, a method like generatePower is simply turned into a memory address in the compiled machine code. That is, when the .exe is compiled, there is no such thing called "generatePower" inside of its bytes. There is no way to know the names of the functions anymore. That information isn't necessary for the program to run, since it can run by knowing just the memory address of the functions instead.
A text like generatePower, with 13 characters would occupy at least 14 bytes of memory (1 for each character plus 1 so we know where it ends). Meanwhile a memory address is always going to be 8 bytes on a 64 bit CPU no matter what we name the function.
Additionally, if functions were referred to by name, we would still have to figure out where their algorithm starts, which would require the program to look up the function by their name. This look up would be very expensive since it would have to be done every single time a function is called and they are called all the time. For these reasons, the original names of fields, methods, and variables aren't preserved in the compiled machine code.
Duck typed programming languages seek the opposite approach. Names used in the source code of a program remain in the program when it runs, so we can tell whether a random object has a method called generatePower or not.
This is the main reason why Python and Javascript have much worse performance than any compiled language. Every time a name of a function is used in one of these languages, a look up has to be performed in one way or another to figure out where is the algorithm to be executed. When a field of an instance is referred to, we need to figure out where are the bytes in memory as well.
These languages used to be much slower due to this, but their performance has improved over the years thanks to many optimizations on how these look ups are performed.
In compiled languages the fields of an object are defined by its class, such that the object can't have more or less fields than defined by the class. After all, the amount of bytes that must be allocated to store that object is also defined by the size of the fields declared in the class declaration.
In duck-typed languages we can take an existing object and add extra fields to it that weren't declared in the class. This means that it's possible to add a generatePower function to ANY object, turning it in an IPowerGenerator.
const myAmazingCat = new Cat();
myAmazingCat.generatePower = function() { /* secret algorithm goes here */ };
battery.charge(cat);As fields and methods may be added to a single random object regardless of what its class declares, the only way to check if a given object fits an abstraction or not is by checking it on a case-by-case basis. In other words, only when the code runs we get to know if it has all the fields or not.
Naturally this would make programming these languages a nightmare—it's much easier to program if you can tell whether there are bugs in a program before it runs—which is why a static type checking system was introduced to both Javascript and Python (as Typescript and type hints, respectively) and practices like adding new fields to random objects are generally frowned upon.